React and Flux
jeremyg3030 (CC BY)Table of Contents
- Introduction
- Getting Started
- Introduction to React
- Setting Up the Project
- Implementing a Note Application
- Deleting Notes
- Understanding React Components
- Editing Notes
- Styling the Notes Application
- Implementing Kanban
- React and Flux
- Implementing NoteStore and NoteActions
- Implementing Persistency over localStorage
- Handling Data Dependencies
- Editing Lanes
- Implementing Drag and Drop
- Advanced Techniques
- Testing React
- Typing with React
- Styling React
- Structuring React Projects
- Appendices
- Language Features
- Understanding Decorators
- Troubleshooting
Nhost - Backend-as-a-Service with GraphQL for modern app development - Interview with Johan Eliasson
You can get pretty far by keeping everything in components. That's an entirely valid way to get started. The problems begin as you add state to your application and need to share it across different parts. This is the reason why various state management solutions have emerged. Each one of those tries to solve the problem in its own way.
The Flux application architecture was the first proper solution to the problem. It allows you to model your application in terms of Actions, Stores, and Views. It also has a part known as Dispatcher to manage actions and allow you to model dependencies between different calls.
This separation is particularly useful when you are working with large teams. The unidirectional flow makes it easy to tell what's going on. That's a common theme in various data management solutions available for React.
Quick Introduction to Redux#
A solution known as Redux took the core ideas of Flux and pushed them to a certain form. Redux is more of a guideline, though a powerful one, that gives your application certain structure and pushes you to model data related concerns in a certain way. You will maintain the state of your application in a single tree which you then alter using pure functions (no side effects) through reducers.
This might sound a little complex but in practice Redux makes your data flow very explicit. Standard Flux isn't as opinionated in certain parts. I believe understanding basic Flux before delving into Redux is a good move as you can see shared themes in both.
Quick Introduction to MobX#
MobX takes an entirely different view on data management. If Redux helps you to model data flow explicitly, MobX makes a large part of that implicit. It doesn't force you to any certain structure. Instead you will annotate your data structures as observable and let MobX handle updating your views.
Whereas Redux embraces the concept of immutability through its idea of reducers, MobX does something opposite and relies on mutation. This means aspects like reference handling can be surprisingly simple in MobX while in Redux you will most likely be forced to normalize your data so that it is easy to manipulate through reducers.
Both Redux and MobX are valuable in their own ways. There's no one right solution when it comes to data management. I'm sure more alternatives will appear as time goes by. Each solution comes with its pros/cons. By understanding the alternatives you have a better chance of picking a solution that fits your purposes at a given time.
Which Data Management Solution to Use?#
The data management situation is changing constantly. At the moment Redux is very strong, but there are good alternatives in sight. voronianski/flux-comparison provides a nice comparison between some of the more popular ones.
When choosing a library, it comes down to your own personal preferences. You will have to consider factors, such as API, features, documentation, and support. Starting with one of the more popular alternatives can be a good idea. As you begin to understand the architecture, you are able to make choices that serve you better.
In this application we'll use a Flux implementation known as Alt. The API is neat and enough for our purposes. As a bonus, Alt has been designed universal (isomorphic) rendering in mind. If you understand Flux, you have a good starting point for understanding the alternatives.
The book doesn't cover the alternative solutions in detail yet, but we'll design our application architecture so that it's possible to plug in alternatives at a later time. The idea is that we isolate our view portion from the data management so that we can swap parts without tweaking our React code. It's one way to design for change.
Introduction to Flux#

So far, we've been dealing only with views. Flux architecture introduces a couple of new concepts to the mix. These are actions, dispatcher, and stores. Flux implements unidirectional flow in contrast to popular frameworks, such as Angular or Ember. Even though two-directional bindings can be convenient, they come with a cost. It can be hard to deduce what's going on and why.
Actions and Stores#
Flux isn't entirely simple to understand as there are many concepts to worry about. In our case, we will model NoteActions and NoteStore. NoteActions provide concrete operations we can perform over our data. For instance, we can have NoteActions.create({task: 'Learn React'}).
Dispatcher#
When we trigger an action, the dispatcher will get notified. The dispatcher will be able to deal with possible dependencies between stores. It is possible that a certain action needs to happen before another. The dispatcher allows us to achieve this.
At the simplest level, actions can just pass the message to the dispatcher as is. They can also trigger asynchronous queries and hit the dispatcher based on the result eventually. This allows us to deal with received data and possible errors.
Once the dispatcher has dealt with an action, the stores listening to it get triggered. In our case, NoteStore gets notified. As a result, it will be able to update its internal state. After doing this, it will notify possible listeners of the new state.
Flux Dataflow#
This completes the basic unidirectional, yet linear, process flow of Flux. Usually, though, the unidirectional process has a cyclical flow and it doesn't necessarily end. The following diagram illustrates a more common flow. It is the same idea again, but with the addition of a returning cycle. Eventually, the components depending on our store data become refreshed through this looping process.
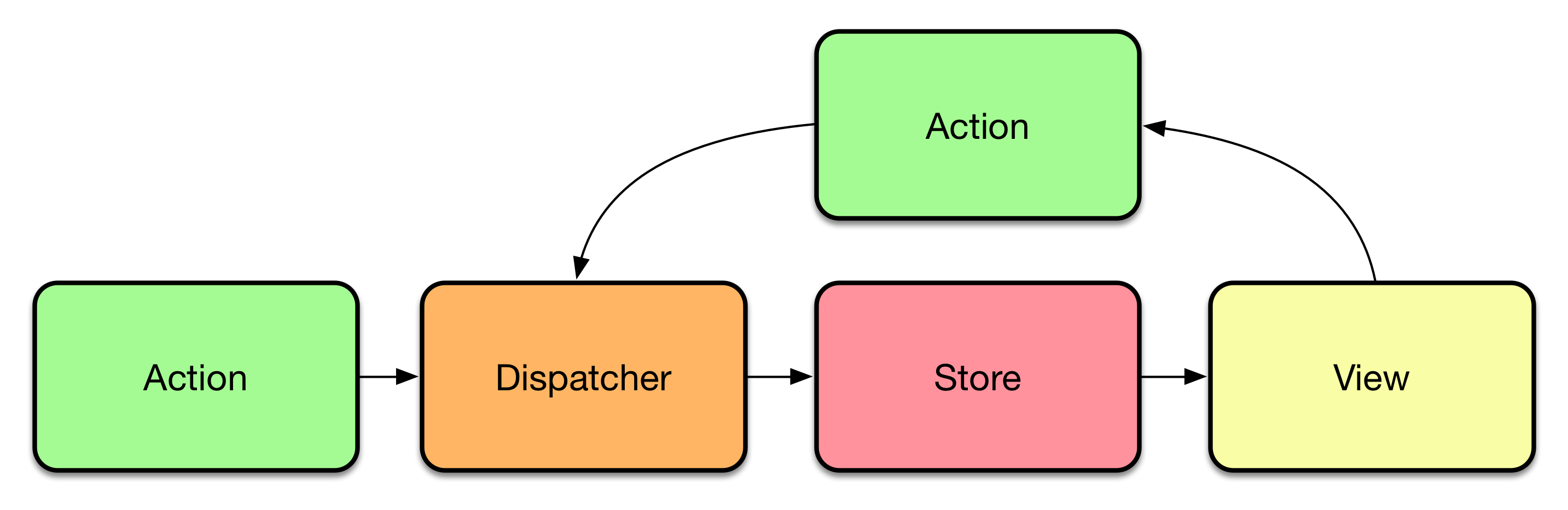
This sounds like a lot of steps for achieving something simple as creating a new Note. The approach does come with its benefits. Given the flow is always in a single direction, it is easy to trace and debug. If there's something wrong, it's somewhere within the cycle.
Better yet, we can consume the same data across our application. You will just connect your view to a store and that's it. This is one of the great benefits of using a state management solution.
Advantages of Flux#
Even though this sounds a little complicated, the arrangement gives our application flexibility. We can, for instance, implement API communication, caching, and i18n outside of our views. This way they stay clean of logic while keeping the application easier to understand.
Implementing Flux architecture in your application will actually increase the amount of code somewhat. It is important to understand that minimizing the amount of code written isn't the goal of Flux. It has been designed to allow productivity across larger teams. You could say that explicit is better than implicit.
Porting to Alt#

In Alt, you'll deal with actions and stores. The dispatcher is hidden, but you will still have access to it if needed. Compared to other implementations, Alt hides a lot of boilerplate. There are special features to allow you to save and restore the application state. This is handy for implementing persistency and universal rendering.
There are a couple of steps we must take to push our application state to Alt:
- Set up an Alt instance to keep track of actions and stores and to coordinate communication.
- Connect Alt with views.
- Push our data to a store.
- Define actions to manipulate the store.
We'll do this gradually. The Alt specific portions will go behind adapters. The adapter approach allows us to change our mind later easier so it's worth implementing.
Setting Up an Alt Instance#
Everything in Alt begins from an Alt instance. It keeps track of actions and stores and keeps communication going on. To keep things simple, we'll be treating all Alt components as a singleton. With this pattern, we reuse the same instance within the whole application.
To achieve this we can push it to a module of its own and then refer to that from everywhere. Configure it as follows:
app/libs/alt.js
import Alt from 'alt';
const alt = new Alt();
export default alt;
This is a standard way to implement singletons using ES6 syntax. It caches the modules so the next time you import Alt from somewhere, it will return the same instance again.
Note thatalt.jsshould go belowapp/libs, not project rootlibs!
The singleton pattern guarantees that there can be only one instance. That is exactly the behavior we want here.
Connecting Alt with Views#
Normally state management solutions provide two parts you can use to connect them with a React application. These are a Provider component and a connect higher order function (function returning function generating a component). The Provider sets up a React context.
Context is an advanced feature that can be used to pass data through a component hierarchy implicitly without going through props. The connect function uses the context to dig the data we want and then passes it to a component.
It is possible to use a connect through function invocation or a decorator as we'll see soon. The Understanding Decorators appendix digs deeper into the pattern.
To keep our application architecture easy to modify, we'll need to set up two adapters. One for Provider and one for connect. We'll deal with Alt specific details in both places.
Setting Up a Provider#
In order to keep our Provider flexible, I'm going to use special configuration. We'll wrap it within a module that will choose a Provider depending on our environment. This enables us to use development tooling without including it to the production bundle. There's some additional setup involved, but it's worth it given you end up with a cleaner result.
The core of this arrangement is the index of the module. CommonJS picks up the index.js of a directory by default when we perform an import against the directory. Given the behavior we want is dynamic, we cannot rely on ES6 modules here.
The idea is that our tooling will rewrite the code depending on process.env.NODE_ENV and choose the actual module to include based on that. Here's the entry point of our Provider:
app/components/Provider/index.js
if(process.env.NODE_ENV === 'production') {
module.exports = require('./Provider.prod');
}
else {
module.exports = require('./Provider.dev');
}
We also need the files the index is pointing at. The first part is easy. We'll need to point to our Alt instance there, connect it with a component known as AltContainer, and then render our application within it. That's where props.children comes in. It's the same idea as before.
AltContainer will enable us to connect the data of our application at component level when we implement connect. To get to the point, here's the production level implementation:
app/components/Provider/Provider.prod.jsx
import React from 'react';
import AltContainer from 'alt-container';
import alt from '../../libs/alt';
import setup from './setup';
setup(alt);
export default ({children}) =>
<AltContainer flux={alt}>
{children}
</AltContainer>
The implementation of Provider can change based on which state management solution we are using. It is possible it ends up doing nothing, but that's acceptable. The idea is that we have an extension point where to alter our application if needed.
We are still missing one part, the development related setup. It is like the production one except this time we can enable development specific tooling. This is a good chance to move the react-addons-perf setup here from the app/index.jsx of the application. I'm also enabling Alt's Chrome debug utilities. You'll need to install the Chrome portion separately if you want to use those.
Here's the full code of the development provider:
app/components/Provider/Provider.dev.jsx
import React from 'react';
import AltContainer from 'alt-container';
import chromeDebug from 'alt-utils/lib/chromeDebug';
import alt from '../../libs/alt';
import setup from './setup';
setup(alt);
chromeDebug(alt);
React.Perf = require('react-addons-perf');
export default ({children}) =>
<AltContainer flux={alt}>
{children}
</AltContainer>
That setup module allows us to perform Alt related setup that's common for both production and development environment. For now it's enough to do nothing there like this:
app/components/Provider/setup.js
export default alt => {}
We still need to connect the Provider with our application by tweaking app/index.jsx. Perform the following changes to hook it up:
app/index.jsx
import React from 'react';
import ReactDOM from 'react-dom';
import App from './components/App';
import Provider from './components/Provider';
if(process.env.NODE_ENV !== 'production') {
React.Perf = require('react-addons-perf');
}
ReactDOM.render(
<App />,
<Provider><App /></Provider>,
document.getElementById('app')
);
If you check out Webpack output, you'll likely see it is installing new dependencies to the project. That's expected given the changes. The process might take a while to complete. Once completed, refresh the browser.
Given we didn't change the application logic in any way, everything should still look the same. A good next step is to implement an adapter for connecting data to our views.
You can see a similar idea in react-redux. MobX won't need a Provider at all. In that case our implementation would simply return children.Understanding connect#
The idea of connect is to allow us to attach specific data and actions to components. I've modeled the API after react-redux. Fortunately we can adapt various data management systems to work against it. Here's how you would connect lane data and actions with App:
@connect(({lanes}) => ({lanes}), {
laneActions: LaneActions
})
export default class App extends React.Component {
render() {
return (
<div>
<button className="add-lane" onClick={this.addLane}>+</button>
<Lanes lanes={this.props.lanes} />
</div>
);
}
addLane = () => {
this.props.laneActions.create({name: 'New lane'});
}
}
The same could be written without decorators. This is the syntax we'll be using in our application:
class App extends React.Component {
...
}
export default connect(({lanes}) => ({lanes}), {
LaneActions
})(App)
In case you need to apply multiple higher order functions against a component, you could use an utility like compose and end up with compose(a, b)(App). This would be equal to a(b(App)) and it would read a little better.
As the examples show, compose is a function returning a function. That's why we call it a higher order function. In the end we get a component out of it. This wrapping allows us to handle our data connection concern.
We could use a higher order function to annotate our components to give them other special properties as well. We will see the idea again when we implement drag and drop later in this part. Decorators provide a nicer way to attach these types of annotations. The Understanding Decorators appendix delves deeper into the topic.
Now that we have a basic understanding of how connect should work, we can implement it.
Setting Up connect#
In this case I'm going to plug in a custom connect to highlight a couple of key ideas. The implementation isn't optimal when it comes to performance. It is enough for this application, though.
It would be possible to optimize the behavior with further effort. You could use one of the established connectors instead or develop your own here. That's one reason why having control over Provider and connect is useful. It allows further customization and understanding of how the process works.
In case we have a custom state transformation defined, we'll dig the data we need from the Provider, apply it over our data as we defined, and then pass the resulting data to the component through props:
app/libs/connect.jsx
import React from 'react';
export default (state, actions) => {
if(typeof state === 'function' ||
(typeof state === 'object' && Object.keys(state).length)) {
return target => connect(state, actions, target);
}
return target => props => (
<target {...Object.assign({}, props, actions)} />
);
}
// Connect to Alt through context. This hasn't been optimized
// at all. If Alt store changes, it will force render.
//
// See *AltContainer* and *connect-alt* for optimized solutions.
function connect(state = () => {}, actions = {}, target) {
class Connect extends React.Component {
componentDidMount() {
const {flux} = this.context;
flux.FinalStore.listen(this.handleChange);
}
componentWillUnmount() {
const {flux} = this.context;
flux.FinalStore.unlisten(this.handleChange);
}
render() {
const {flux} = this.context;
const stores = flux.stores;
const composedStores = composeStores(stores);
return React.createElement(target,
Object.assign(
{}, this.props, state(composedStores), actions
)
);
}
handleChange = () => {
this.forceUpdate();
}
}
Connect.contextTypes = {
flux: React.PropTypes.object.isRequired
}
return Connect;
}
// Transform {store: <AltStore>} to {<store>: store.getState()}
function composeStores(stores) {
let ret = {};
Object.keys(stores).forEach(k => {
const store = stores[k];
// Combine store state
ret = Object.assign({}, ret, store.getState());
});
return ret;
}
As flux.FinalStore won't be available by default, we'll need to alter our Alt instance to contain it. After that we can access it whenever we happen to need it:
app/libs/alt.js
import Alt from 'alt';
import makeFinalStore from 'alt-utils/lib/makeFinalStore';
const alt = new Alt();
export default alt;
class Flux extends Alt {
constructor(config) {
super(config);
this.FinalStore = makeFinalStore(this);
}
}
const flux = new Flux();
export default flux;
In order to see connect in action, we could use it to attach some dummy data to App and then render it. Adjust it as follows to pass data test to App and then show it in the user interface:
app/components/App.jsx
import React from 'react';
import uuid from 'uuid';
import Notes from './Notes';
import connect from '../libs/connect';
export default class App extends React.Component {
class App extends React.Component {
constructor(props) {
...
}
render() {
const {notes} = this.state;
return (
<div>
{this.props.test}
<button className="add-note" onClick={this.addNote}>+</button>
<Notes
notes={notes}
onNoteClick={this.activateNoteEdit}
onEdit={this.editNote}
onDelete={this.deleteNote}
/>
</div>
);
}
...
}
export default connect(() => ({
test: 'test'
}))(App)
To make the text show up, refresh the browser. You should see the text that we connected to App now.
Dispatching in Alt#
Even though you can get far without ever using Flux dispatcher, it can be useful to know something about it. Alt provides two ways to use it. If you want to log everything that goes through your alt instance, you can use a snippet, such as alt.dispatcher.register(console.log.bind(console)). Alternatively, you could trigger this.dispatcher.register(...) at a store constructor. These mechanisms allow you to implement effective logging.
Other state management systems provide similar hooks. It is possible to intercept the data flow in many ways and even build custom logic on top of that.
Conclusion#
In this chapter we discussed the basic idea of the Flux architecture and started porting our application to it. We pushed the state management related concerns behind an adapter to allow altering the underlying system without having to change the view related code. The next step is to implement a store for our application data and define actions to manipulate it.
This book is available through Leanpub. By purchasing the book you support the development of further content.